In this section, we assume you own the standalone Latent Class v4.0 (or v2.5) software and have prepared a .CHO file containing respondent data. You obtained the .CHO file by clicking File | Data Management | Export Data and by adding an export job that has an Export Settings Type of MaxDiff. Or, if using the paper-and-pencil data collection procedure, you would have generated a .CHO file using the MaxDiff Experiment Designer software.
When you export a .CHO file from Lighthouse Studio, the following additional files are created for use in Latent Class v4:
ExerciseName.ATT (Attribute file)
ExerciseName.EFF (Effects file)
ExerciseName.VAL (Values file)
These files are all described in the Latent Class software documentation—but they have been formatted in special ways to accommodate MaxDiff analysis. (Note, Latent Class v4 is required for MaxDiff estimation. If you are licensed with Latent Class v3.x, you can obtain a free copy of v4 from Sawtooth Software)
For your information, the formats for the files automatically created by Lighthouse Studio are described below:
ExerciseName.ATT is also a text-only file, containing labels for the items (attributes) in your MaxDiff study (remember, if you have 8 items in total, you'll be using n-1, or 7 labels in the .ATT file). To conform to the rule in standard Latent Class that each attribute have at least two levels, we represent each MaxDiff item as a two-level attribute. For example, your ExerciseName.ATT file should contain:
Red
(use a single blank line here to separate the levels)
Red
(use two blank lines here to separate attributes, etc.)
Green
Green
Blue
Blue
ExerciseName.EFF is a text-only file, containing the attribute numbers to be used in analysis. If you have 8 items in total in your MaxDiff study, you need to follow a dummy-coding procedure in which you estimate n-1 or 7 parameters (the utility of the omitted parameter is set to zero, and all other utilities are scaled relative to the omitted item). Assuming 8 items, specify the following on the first line of your ExerciseName.EFF file:
#1 #2 #3 #4 #5 #6 #7
The "pound notation" is specialized for use when the analyst wishes to override the typical effects-coding procedure that Latent Class v2 uses for conjoint data.
ExerciseName.VAL is also required whenever using "pound notation," and is a text-only file with two lines per item in your study. Again, assuming an 8 item study, you are only estimating 7 parameters, and your ExerciseName.VAL file should have 14 total lines (2 for each of the 7 parameters). The first six lines look like:
"Attribute 1 Label"
1 2
"Attribute 2 Label"
1 2
"Attribute 3 Label"
1 2 (etc.)
Although we are only estimating a single parameter for each attribute, we list the level values as "1" and "2." This is just to satisfy the Latent Class software (which was designed for conjoint experiments, where every attribute has at least two levels), and to ensure that the scaling of data in the text report that we produce is proper.
Running Latent Class
Start Latent Class v4 by clicking Start | Programs | Sawtooth Software | Sawtooth Software Latent Class. Click File | Open. Browse to the .CHO file created by the MaxDiff Designer software.
On the Attribute Information tab, modify all attributes to have "User-specified coding." (Note that there will be k-1 total attributes in the study, representing your k total items in the MaxDiff design.)
Click Estimate Parameters Now... from the Home tab. Utility values are written to the .LCU and .CSV files. Remember, the utility of the omitted value for each group is 0, and the other items are measured with respect to that omitted item.
Transforming Weights to 0-100 Scale
To convert the raw weights to the 0-100 point scale, first zero-center the weights by subtracting the mean weight for each segment from each segment's weights. Then, perform the following transformation for each zero-centered item score for each segment:
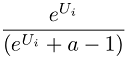
Where:
Ui = zero-centered raw logit weight for item i
eUi is equivalent to taking the antilog of Ui. In Excel, use the formula =EXP(Ui)
a = Number of items shown per set
Finally, as a convenience, we rescale the transformed item scores by a constant multiplier so that they sum to 100.
The logic behind this transformation is as follows: We are interested in transforming raw scores (developed under the logit rule) to probabilities true to the original data generation process (the counts). If respondents saw 4 items at a time in each MaxDiff set, then the raw logit weights are developed consistent with the logit rule and the data generation process. Stated another way, the scaling of the weights will be consistent within the context (and assumed error level) of choices from quads. Therefore, if an item has a raw weight of 2.0, then we expect that the likelihood of it being picked within the context of a representative choice set involving 4 items is (according to the logit rule):
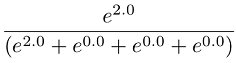
Since we are using zero-centered raw utilities, the expected utility for the competing three items within the set would each be 0.0. Since e0 = 1, the appropriate constant to add to the denominator of the rescaling equation above is the number of alternatives minus 1.
Note: Prior to SSI Web v6.2, we used a different rescaling procedure that assumed that the scaling of the logit weights was consistent with a data generation process of respondents picking one item from t items, where t was the total number of items in the experiment. However, upon further review, this assumption provided scaling that was too extreme when considering the actual data generation process (where items are being chosen from subsets of items much smaller than t). The benefit of the new scaling procedure is that you will note fewer inconsistencies between the summary raw scores and probability-scaled scores for the population. The new probability-scaled estimates for the population will be more stable.