Automatically determine iterations per respondent
By default, Randomized First Choice conducts multiple iterations (shopping trips) for each respondent. In each iteration, the part-worth utilities are perturbed by random error. Because there is a random component to the process, the results are made more precise (more stable) by performing more iterations. The simulator has defaults built in that yield good precision, as shown below:
Number of Products in Simulation Scenario |
Number of RFC Sampling Iterations across Respondents |
<10 |
250,000 |
10 to 24 |
750,000 |
25 to 49 |
1,500,000 |
50 to 99 |
2,500,000 |
100+ |
5,000,000 |
You can increase or reduce the precision by un-checking the Automatically determine iterations per respondent box and then specifying the number of iterations per respondent. When conducting product searches with Randomized First Choice, initially you may wish to reduce the number of iterations significantly from the defaults to speed up the process; then, after reducing the search space to the most likely optimal outcomes, you might increase the iterations to obtain greater precision.
For market simulation scenarios involving just a few products (say, less than 10), 250000 total iterations across respondents are often enough to obtain good precision. So, if you have 250 respondents, you could specify 1000 iterations per respondent. If you want to double the number of iterations across respondents to 500000 in this case, you would specify 2000 iterations per respondent (assuming n=250).
For market simulation scenarios involving many products (say, 25 or more), 1 million or more iterations across respondents may be needed to obtain good precision (because each share of preference is much smaller in absolute terms, so the effect of the random process is relatively larger). If you have 250 respondents, you may wish to increase the number of iterations per respondent to 4000 or more per respondent (assuming n=250).
Attribute variability
By default, Randomized First Choice automatically determines the appropriate attribute variability multiplier (which determines the variance of the random perturbations) that will yield shares of preference with approximately the same scale factor (steepness or flatness of shares of preference) as the Share of Preference method. However, if you want to override those default settings, you may check this box and specify a value 0 or greater. Larger values cause the relative shares to be flatter. Smaller values cause the relative shares to be steeper.
Apply correlated error (correction for similarity) to the following attributes
Some attributes would seem to not justify any correction for product similarity. Correcting for product similarity for the Price attribute is problematic, particularly leading to strange kinks in derived demand curves for pricing studies (see charts below).
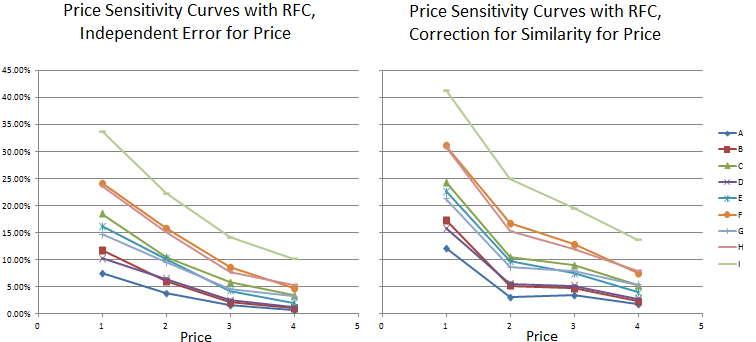
In the examples above, demand curves were simulated via sensitivity analysis across the four levels of price for nine brands (A-I), where price level 2 was the default level that products were fixed at while the test product's price was varied. When RFC's correction for product similarity is turned on for price, as the test brand's price changes from price 2 to another price while the other 8 brands are held fixed at price 2, too much reward (for uniqueness) is given to the unique product that is no longer at price 2. This leads to bias in the products' shares on prices other than price 2, a strange kink, and even an unexpected reversal for the lowest share brand A when it increases its price from 2 to 3. We also compared RFC results to standard Share of Preference simulations for these demand curves and found RFC without correlated error (above left) to be extremely similar to the demand curves using Share of Preference, whereas the results with correlated error (above right) deviated significantly.
We generally recommend you un-check the Apply Correlated Error box for your price attribute. When an attribute is un-checked in this dialog, independent attribute error is drawn for this attribute across the product concepts within the simulation scenario.
Product variability
By default, no product variability error perturbation is used in Randomized First Choice. However, the model supports it if you wish to introduce some degree of IIA behavior into the simulation results. Specifying a value larger than 0 introduces independent error applied to the total sum of utility for each product concept. For example, a value of 0.2 as the error multiplier would introduce some degree of IIA behavior. Adding some product variability to the RFC simulation will also decrease the steepness of the resulting shares of preference.